How this tutorial works
Wait for a molecule to appear in the left window before
proceeding. Click on the 'X' button next to the description to make the
change to the molecule described. Click on the '?' button for an explanation
of what is being done to the molecule. Explanations appear in this window.
See this explanation again by hitting the '?' next to 'Help' in the window
below . The molecule in the window to the left can be further manipulated
using the mouse. Hit the Mouse Icon to learn to rotate, zoom, render etc. 
.
.
.
.
.
.
.
.
.
.
.
Nucleotide - Stick representation
A guanine nucleotide. The molecule is shown in a skeletal
representation, which shows its structural formula and sterochemistry well.
We use a convention here, called "CPK colours", to identify the atoms.
Carbons are grey; oxygens are red; nitrogens are blue; phosphates are orange.
The ribose units polymerise through their 5' phosphate
groups and 3' OH groups with other nucleotides to form a polynucleotide
backbone.
A disadvantage of the wireframe representation is that
it makes molecules look as if they are mostly empty space. In fact the
atoms are often tightly packed. Click the next x on the right-hand panel
to see the atoms at their full Van derWaals radii.
.
.
.
.
.
.
.
.
.
.
.
Nucleotide -spacefilling
A guanine nucleotide, as shown by the previous button, is
represented with the atoms set to their Van derWaals radii. The atoms are
coloured: grey for carbons; red for oxygens; blue for nitrogens;phosphates
are orange.
.
.
.
.
.
.
.
.
.
.
.
Add a nucleotide to 3' OH
A cytosine nucleotide is shown condensed to the original
guanine nucleotide shown in the previous example. The link is between the
3'OH of the G base with the 5' phosphate of the C base, which forms the
new 3' end.
.
.
.
.
.
.
.
.
.
.
.
Add another nucleotide to 3' OH
An adenine nucleotide is shown condensed to the original
guanine -cytosine dinucleotide shown in the previous example. The link
is between the 3'OH of the C base of the dinucleotide with the 5' phosphate
of the A base at the 3' end.
.
.
.
.
.
.
.
.
.
.
.
Add another nucleotide to 5' OH
An adenine nucleotide is shown condensed to the guanine-cytosine-adenine
trinculeotide in the previous example. The link is between the 3'OH of
the adding A base with the 5' phosphate of the G base at the 5' end of
the trinculeotide.
.
.
.
.
.
.
.
.
.
.
.
Add complementary strand
The polynucleotide in the last example ran from 5' at bottom
of the screem to 3' at the top. The complementary strand runs in the opposite
direction. Complementary bases pairs ( A:T and G:C) make hydrogen bonds.
.
.
.
.
.
.
.
.
.
.
.
Show double stranded DNA
We show the double stranded, complementary base pairs as
shown in the cartoon before question 1. The single stranded overhang is
shown in the next image.
.
.
.
.
.
.
.
.
.
.
.
Show double stranded DNA with single stranded
overhang
The single stranded, poly T, overhang is shown in addition
to the double stranded DNA.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix
This purpose of this section is to help you to recognise
secondary structural elements, alpha helices and beta strands, and the
different ways in which they are sometimes represented. Here we show an
alpha helix in wireframe mode. Usually protein structure contain so many
atoms that it is difficult to understand them. That is why we use molecular
graphics to simply them and to display the molecule in different ways that
best fit our purpose. In the next section, we shall highlight the backbone,
which allows us to see the direction of the mainchain better.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix backbone
In green we highlight the backbone ( ie amide nitrogen, alpha
carbon, carbonyl carbon, carbonyl oxygen). Note how the side-chains are
angled away from the helix. They have the appearance of an arrow-head that
points from N-terminus of the helix towards its C-terminus. In the next
image we simplify the structure even more by just drawing links between
the backbone alpha carbons.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix trace through alpha carbons
Here we show bonds that link alpha carbons. Of course, alpha
carbons are actually linked by two other backbone atoms. So bonds linking
alpha carbons are 'virtual' bonds. The value of this representation is
that it simplifies an alpha helix so that it is instantly recognisable.
The down side is that we lose information about which direction ( N-terminus
to C-terminus)the helix is running unless we click on atoms and find in
which direction the sequence runs.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand - wireframe
This shows a beta strand in a wireframe representation. It
is fairly easy to see the backbone. Rotate the molecule about to appreciate
the 'pleated' nature of the backbone, as sidechain are found alternatively
on either side of the backbone. The next image highlights the backbone.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand - backbone
The backbone of the beta strand shown in the previous image
is highlighted in green.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand trace through alpha carbons
Here we show bonds that link alpha carbons. Of course, alpha
carbons are actually linked by two other backbone atoms. So bonds linking
alpha carbons are 'virtual' bonds. The value of this representation is
that it simplifies a beta strand so that it is instantly recognisable.
.
.
.
.
.
.
.
.
.
.
.
Display Helicase: DNA; ATP form
Here we show a crystal structure of a helicase with bound
DNA with a single stranded overhang and bound ATP. If you have worked through
the previous sections, you will find recognise DNA and the single stranded
overhang. The protein is shown as a trace through the alpha carbons. It
folds into four domains. These are all part of the same chain but form
distinct globular regions of the protein. They have been coloured green
for domain 1a and red for domain 2a. ATP, shown as a spacefilling model,
is found in a cleft between these two domains. The blue and yellow domains
bind the double stranded region of the DNA. The single stranded DNA binds
across the tops of the red and green domains.
.
.
.
.
.
.
.
.
.
.
.
Display Helicase: DNA; ATP form
Here the phosphate form of the helicase complex. The colour
scheme is the same as the previous image. The difference is that phosphate,
not ATP, is found in the cleft between the green and red domains. Also,
the single stranded DNA has moved. We show its position in the phosphate
structure in magenta. For comparison we leave its former position in the
ATP structure, as in the last image.
.
.
.
.
.
.
.
.
.
.
.
Display ssDNA before and after hydrolysis of ATP.
Position of single stranded DNA before hydrolysis of DNA
is shown with carbon atoms in grey. The position of the same polynucleotide
after ATP is hydrolysed is shown with carbons in magenta. You will see
that the 3' phosphate groups of the ss DNA in the ATP form (grey carbons)
almost overlaps with the penultimate phosphate of the ssDNA after ATP hydrolysis
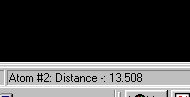
(purple atoms). Your task is to measure how far, in Å, the end of
the ssDNA has been translocated in the ATP structure with respect to the
phosphate structure. You do this by clicking each in turn. The distance
is displayed in Angstoms at the bottom of the frame that encompasses your
browser. An example is given below for a distance that measures 13.508
Angstroms ( not the correct answer!).
.
.
.
.
.
.
.
.
.
.
.
Toggle between ATP and Phosphate Structures.
Hit the X button to toggle between structures of the helicase
with bound ATP or bound phosphate. You can tell which is which by the labelled
molecule ( ATP or phosphate) in the cleft between the red and green domains.
Phe 64 and Tyr 257 are shown as green, spacefilling molecules. These change
position relative to each other when the red and green domains undergo
a conformation change when ATP is hydrolysed. Double stranded DNA and the
single stranded overhang are shown for both conformations for reference.
The changed position of the ssDNA in the phosphate structure is highlighted
by showing its carbons in magenta. .
.
.
.
.
.
.
.
.
.
.
.
Map mutant C901Y in Bloom Syndrome.
A mutation has been identified in the helicase associated
with Bloom's syndrome at position 901 in which a cysteine (C) in the normal
protein becomes a tyrosine (Y) in the affected person. We do not have a
structure for the Bloom's Syndrome Helicase. But we have shown that certain
sequence motifs are highly conserved in both the Bloom helicase and the
helicase whose structures we have shown here. Thus we can map the mutation
in the Bloom helicase onto that of the known helicase in order to learn
which part of the structure may be affected. Here we show the corresponding
residue position in the helicase structure as a magenta coloured stick-representation.
The surrounding residues within 8 Angstroms are shown with normal cpk colours.
.
.
.
.
.
.
.
.
.
.
.
.
Map mutant Q672R in Bloom Syndrome.
A mutation has been identified in the helicase associated
with Bloom's syndrome at position 672 in which a glutamine (Q) in the normal
protein becomes an arginine (R) in the affected person. We do not have
a structure for the Bloom's Syndrome Helicase. But we have shown that certain
sequence motifs are highly conserved in both the Bloom helicase and the
helicase whose structures we have shown here. Thus we can map the mutation
in the Bloom helicase onto that of the known helicase in order to learn
which part of the structure may be affected. Here we show the corresponding
residue position in the helicase structure as a magenta coloured spacefilling
residue. .
.
.
.
.
.
.
.
.
.
.
.
How this tutorial works
Wait for a molecule to appear in the left
window before proceeding. Click on the 'X' button next to the description
to make the change to the molecule described. Click on the '?' button for
an explanation of what is being done to the molecule. Explanations appear
in this window. See this explanation again by hitting the '?' next to 'Help'
in the window below . The molecule in the window to the left can be further
manipulated using the mouse. Hit the Mouse Icon to learn to rotate, zoom,
render etc.
.
.
.
.
.
.
.
.
.
.
.
Nucleotide - Stick representation
A guanine nucleotide. The molecule is shown in a skeletal
representation, which shows its structural formula and sterochemistry well.
We use a convention here, called "CPK colours", to identify the atoms.
Carbons are grey; oxygens are red; nitrogens are blue; phosphates are orange.
The ribose units polymerise through their 5' phosphate
groups and 3' OH groups with other nucleotides to form a polynucleotide
backbone.
A disadvantage of the wireframe representation is that
it makes molecules look as if they are mostly empty space. In fact the
atoms are often tightly packed. Click the next x on the right-hand panel
to see the atoms at their full Van derWaals radii.
.
.
.
.
.
.
.
.
.
.
.
Nucleotide -spacefilling
A guanine nucleotide, as shown by the previous button, is
represented with the atoms set to their Van derWaals radii. The atoms are
coloured: grey for carbons; red for oxygens; blue for nitrogens;phosphates
are orange.
.
.
.
.
.
.
.
.
.
.
.
Add a nucleotide to 3' OH
A cytosine nucleotide is shown condensed to the original
guanine nucleotide shown in the previous example. The link is between the
3'OH of the G base with the 5' phosphate of the C base, which forms the
new 3' end.
.
.
.
.
.
.
.
.
.
.
.
Add another nucleotide to 3' OH
An adenine nucleotide is shown condensed to the original
guanine -cytosine dinucleotide shown in the previous example. The link
is between the 3'OH of the C base of the dinucleotide with the 5' phosphate
of the A base at the 3' end.
.
.
.
.
.
.
.
.
.
.
.
Add another nucleotide to 5' OH
An adenine nucleotide is shown condensed to the guanine-cytosine-adenine
trinculeotide in the previous example. The link is between the 3'OH of
the adding A base with the 5' phosphate of the G base at the 5' end of
the trinculeotide.
.
.
.
.
.
.
.
.
.
.
.
Add complementary strand
The polynucleotide in the last example ran from 5' at bottom
of the screem to 3' at the top. The complementary strand runs in the opposite
direction. Complementary bases pairs ( A:T and G:C) make hydrogen bonds.
.
.
.
.
.
.
.
.
.
.
.
Show double stranded DNA
We show the double stranded, complementary base pairs as
shown in the cartoon before question 1. The single stranded overhang is
shown in the next image.
.
.
.
.
.
.
.
.
.
.
.
Show double stranded DNA with single stranded
overhang
The single stranded, poly T, overhang is shown in addition
to the double stranded DNA.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix
This purpose of this section is to help you to recognise
secondary structural elements, alpha helices and beta strands, and the
different ways in which they are sometimes represented. Here we show an
alpha helix in wireframe mode. Usually protein structure contain so many
atoms that it is difficult to understand them. That is why we use molecular
graphics to simply them and to display the molecule in different ways that
best fit our purpose. In the next section, we shall highlight the backbone,
which allows us to see the direction of the mainchain better.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix backbone
In green we highlight the backbone ( ie amide nitrogen, alpha
carbon, carbonyl carbon, carbonyl oxygen). Note how the side-chains are
angled away from the helix. They have the appearance of an arrow-head that
points from N-terminus of the helix towards its C-terminus. In the next
image we simplify the structure even more by just drawing links between
the backbone alpha carbons.
.
.
.
.
.
.
.
.
.
.
.
Show alpha helix trace through alpha carbons
Here we show bonds that link alpha carbons. Of course, alpha
carbons are actually linked by two other backbone atoms. So bonds linking
alpha carbons are 'virtual' bonds. The value of this representation is
that it simplifies an alpha helix so that it is instantly recognisable.
The down side is that we lose information about which direction ( N-terminus
to C-terminus)the helix is running unless we click on atoms and find in
which direction the sequence runs.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand - wireframe
This shows a beta strand in a wireframe representation. It
is fairly easy to see the backbone. Rotate the molecule about to appreciate
the 'pleated' nature of the backbone, as sidechain are found alternatively
on either side of the backbone. The next image highlights the backbone.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand - backbone
The backbone of the beta strand shown in the previous image
is highlighted in green.
.
.
.
.
.
.
.
.
.
.
.
Show beta strand trace through alpha carbons
Here we show bonds that link alpha carbons. Of course, alpha
carbons are actually linked by two other backbone atoms. So bonds linking
alpha carbons are 'virtual' bonds. The value of this representation is
that it simplifies a beta strand so that it is instantly recognisable.
.
.
.
.
.
.
.
.
.
.
.
Display Helicase: DNA; ATP form
Here we show a crystal structure of a helicase with bound
DNA with a single stranded overhang and bound ATP. If you have worked through
the previous sections, you will find recognise DNA and the single stranded
overhang. The protein is shown as a trace through the alpha carbons. It
folds into four domains. These are all part of the same chain but form
distinct globular regions of the protein. They have been coloured green
for domain 1a and red for domain 2a. ATP, shown as a spacefilling model,
is found in a cleft between these two domains. The blue and yellow domains
bind the double stranded region of the DNA. The single stranded DNA binds
across the tops of the red and green domains.
.
.
.
.
.
.
.
.
.
.
.
Display Helicase: DNA; phosphate form
Here the phosphate form of the helicase complex is shown.
The colour scheme is the same as the previous image. The difference is
that phosphate, not ATP, is found in the cleft between the green and red
domains. Also, the single stranded DNA has moved. We show its position
in the phosphate structure in magenta. For comparison we leave its former
position in the ATP structure, as in the last image.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Toggle between ATP and Phosphate Structures.
Hit the X button to toggle between structures of the helicase
with bound ATP or bound phosphate. You can tell which is which by the labelled
molecule in the cleft between the red and green domains. Phe 64 and Tyr
257 are shown as green, spacefilling molecules. These change position relative
to each other when the red and green domains undergo a conformation change
when ATP is hydrolysed. Double stranded DNA and the single stranded overhang
are shown for both conformations for reference. The changed position of
the ssDNA in the phosphate structure is highlighted by showing its carbons
in magenta. .
.
.
.
.
.
.
.
.
.
.
.
Map mutant C901Y in Bloom Syndrome.
A mutation has been identified in the helicase associated
with Bloom's syndrome at position 901 in which a cysteine (C) in the normal
protein becomes a tyrosine (Y) in the affected person. We do not have a
structure for the Bloom's Syndrome Helicase. But we have shown that certain
sequence motifs are highly conserved in both the Bloom helicase and the
helicase whose structures we have shown here. Thus we can map the mutation
in the Bloom helicase onto that of the known helicase in order to learn
which part of the structure may be affected. Here we show the corresponding
residue position in the helicase structure as a magenta coloured stick-representation.
The surrounding residues within 8 Angstroms are shown with normal cpk colours.
.
.
.
.
.
.
.
.
.
.
.
.
Map mutant Q672R in Bloom Syndrome.
A mutation has been identified in the helicase associated
with Bloom's syndrome at position 672 in which a glutamine (Q) in the normal
protein becomes an arginine (R) in the affected person. We do not have
a structure for the Bloom's Syndrome Helicase. But we have shown that certain
sequence motifs are highly conserved in both the Bloom helicase and the
helicase whose structures we have shown here. Thus we can map the mutation
in the Bloom helicase onto that of the known helicase in order to learn
which part of the structure may be affected. Here we show the corresponding
residue position in the helicase structure as a magenta coloured spacefilling
residue. .
.
.
.
.
.
.
.
.
.
.
.
Map mutant I841T in Bloom Syndrome.
A mutation has been identified in the helicase associated
with Bloom's syndrome at position 841 in which an isoleucine (I) in the
normal protein becomes a threonine (T) in the affected person. We do not
have a structure for the Bloom's Syndrome Helicase. But we have shown that
certain sequence motifs are highly conserved in both the Bloom helicase
and the helicase whose structures we have shown here. Thus we can map the
mutation in the Bloom helicase onto that of the known helicase in order
to learn which part of the structure may be affected. Here we show the
corresponding residue position in the helicase structure as a magenta coloured
spacefilling residue. .
.
.
.
.
.
.
.
.
.
.
.
Display conserved motifs.
The ATP structure is shown. The trace through the alpha carbon
co-ordinates is shown in white. The seven regions in the sequence that
are found to be similar in a number of different helicases, even if the
organisms are distantly related, are highlighted in colour: region I (cyan);
region Ia (magenta); region II (blue); region III (orange); region IV(red);
region V (yellow); region VI (green) .
.
.
.
.
.
.
.
.
.
.
.
Display 5'-3' Helicase Rec D2
The nucleotide free structure of Deinococcus radiodurans Rec D2 is shown. This is a
5'-3' Helicase. Domain 1A is green, 2A is red. The insertion in 1A, 1B, is shown in yellow. The insertion in 2A, 2B, is blue.
The yellow domain forms a "pin" over which the ds DNA is thought to be split.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Display 5'-3' Helicase Rec D2
The nucleotide bound structure of Deinococcus radiodurans Rec D2 is shown. The ATP non-hydrolyzable analogue AMPPNP
is shown in spacefilling.Domain 1A is green, 2A is red. The insertion in 1A, 1B, is shown in yellow. The insertion in 2A, 2B, is blue.
The yellow domain forms a "pin" over which the ds DNA is thought to be split.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Display ssDNA before and after hydrolysis of ATP in Deinococcus radiodurans Rec D2.
Position of single stranded DNA before hydrolysis of DNA
is shown with carbon atoms in grey. The position of the same polynucleotide
after ATP is hydrolysed is shown with carbons in magenta. You will see
that the 5' base before hydrolysis has sequence number 1: afterwards ATP binding the position
of the base(magenta) in this position is number 2. So the bases have moved towards the 5' end.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Toggle between ATP and Phosphate Structures in Deinococcus radiodurans Rec D2.
Hit the X button to toggle between structures of the helicase
with bound ATP or bound phosphate. The N-terminal domain and the blue 2B domain have been removed for clarity.
The dsDNA is probably separated over the pin domain, which is domain 1B, yellow, in this case. Base 5 in the
nucleotide free form is flipped out, and like in the PcrA case, it is bound in a pocket. But the position equivalent to
F64, is now P389. This shorter side-chain doesn't base-stack and so the pocket is more open. The other side of the pocket
is formed by V470. After ATP binding there is a
rotation of 1A(green) vs 1B(red). Now base 5 is out of the pocket and V470 seems to form a racket between base 5 and base 4.
V470 is motif 3, which in PcrA contains Y257 that forms the other side of binding pocket. V470 is a few residues from the
equivalent residue in Rec D2.
.
.
.
.
.as
.
.
.
.
.
.
| Action |
Windows |
Macintosh |
| MENU |
Right |
Hold Down |
| Rotate X,Y |
Left |
Unmodified |
| Translate X,Y |
Ctrl-Right# |
Command* |
| Rotate Z |
Shift-Right |
Shift-Command* |
| Zoom |
Shift-Left |
Shift |
| Slab Plane |
Ctrl-Left |
Ctrl |
*On some Macs, the Option (Alt) key has the same effect on
RasMol as the Command key.
#Simply Right in RasWin. This is the only mouse
control which differs between Chime and RasWin.
.
.
.
.
.
.
.
.
.
.
.