From the course
essay you will be aware of the importance of searching
sequence databases to identify a gene product. The aim of
this project is to give you access to the same tools that practising
molecular
cell biologists use to do this. We also want you to report your results
using PowerPoint. This will teach you how to convey information in a
succinct,
graphical manner and to learn some elementary skills in using
presentation
software (all transferable skills).
Aims and Outcomes
Understand the principles of a "pull down" experiment to identify
other proteins that interact with a protein of interest
Understand the principles by which a novel protein can be
identified by MALDI-TOF analysis of its tryptic peptides
Use a on-line database to identify the novel protein
Find any annotated domains within the identified protein.
Find the pI and MW of the protein.
Report on the function of the identified protein.
Create a PowerPoint slide to report your findings.
Upload your Powerpoint slide onto the course Web site.
Overview
Many interesting
problems in cell biology involve protein complexes.
Indeed, a systematic analysis of protein interactions in S.cerevisiae
showed that lone proteins are the exception. On average, each protein
has five interactors.
The link below
explains the pulldown technique and how MALDI-TOF analysis of tryptic
peptides from the interactor can be used to identify it. Subsequently the
amino-acid sequence can be analysed for the signature of protein
domains, such as SH2 and SH3 domains, which sometimes aid efforts to
work out the function of the protein.
For this
exercise you are presented with a research scenario, common in many
aspects of mocleular cell biology, which takes you through this process
and should allow you to propose a model for how the system might work.
Your understanding of this exercise will be tested in the ICA test.
You will receive individual feedback and, on successful completion of
the
task, a grade of 1 will appear in your marks. This mark is not
itself
part of your ICA, but it does signify that you have successfully
completed
the task as part of your DP for the course.
The Scenario -
Investigation of interacting proteins with Anyport,
a Drosophila protein involved
in Axonal Guidance.
You
are studying a Drosophila protein, Anyport, which
consists of three SH3
domains and one SH2 domain.One of SH3
domains of Anyport protein was shown to bind and activate a kinase,
Pak, which regulates the actin cytoskeleton.Interestingly
a mutant lacking Anyport shows axon guidance defects in Drosophila
embryos.Axon guidance requires correct
recognition of the target and regulation of axon growth.
As SH2 domain is known to
bind a short sequence containing a phosphorylated tyrosine, you thought
identification of proteins which bind to this SH2 domain would be
crucial to understand a role of Anyport in axon guidance.
One night you had a
brilliant idea.You made a plasmid
expressing a protein which contains the SH2 domain of Anyport fused
with pentahistidine.You transfected this
plasmid to Drosophila cultured cells and pull down
this fusion protein using nickel beads which binds to pentahistidine.
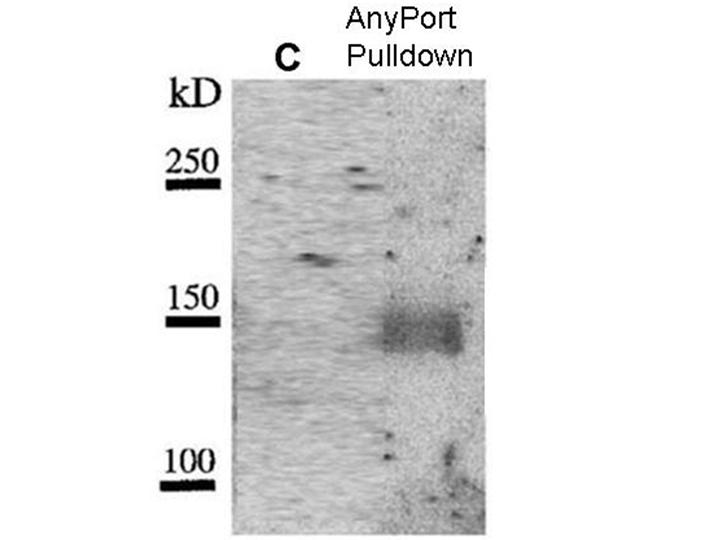
Results of
pulldown experiment
You do a suitable control
experiment(C). In both experiments
you
spin down the beads and subject them to SDS polyacrylamide gel
electrophoresis.To visualise bands that
bind to Anyport you overlay the gel with a purified construct that
expresses radioactive SH2 domain of Anyport.
MALDI-TOF
analysis
You cut this band out
and subject it to trypsin hydrolysis. The peptides are subjected to
MALDI-TOF
analysis. Some of the m/z masses found are:
Select the m/z
values for the tryptic peptides derived from the novel
protein. Drag the mouse over the values in the table above while
depressing the left mouse
button. Copy it either by right clicking and then selecting
Copy in the menu, or hit Ctrl-C, or in the top tool
bar,
hit Edit and then Copy in the drop-down
menu.
Then click the
following button to access a web-server that
interrogates a database of precomputed tryptic peptides to identify any
unique signature that may be your protein (
http://prospector.ucsf.edu/prospector/4.0.7/html/msfit.htm)
The parts of the form that you have to change are shown
Scroll down to "Data
Paste Area". You need to delete the values
that are there. Either put your cursor in the area, hit Ctrl-A, then
delete or drag the cursor over all the values, and then finally hit
delete.
Now paste your values either by hitting Ctrl-V, or in the top
tool bar,
hit Edit and then Paste in the drop-down menu, or
right-click and select Paste
from the drop-down menu.
Set the masses of the peptides to "Average", not
"Monoisotopic". Just above the "Data Paste" area, change "Peptide
masses are monoisotopic" to "Peptide masses are average" by selecting
"average" from the drop down menu.
To speed up the search we may limit the sizes of the
protein that the server must search. Look at the pulldown experiment.
What is the size of the protein we are looking for? Scroll up to "Mw of
Protein : ( from 1000 Da to 100000 Da). Change this to a more sensible
limit. Note that the mw from SDS- Polyacrylamide electrophoresis is
never precise and that some proteins may run anomalously. So
don't make your limits too narrow ( Hint: there are not many proteins
larger than 100,000 Da).
Hit "Start Search"
Results
Look for the
result with the highest percentage of input peptides that
are matched, not the MOWSE score ( see (i) in the example). Open the
link to the sequence (see example below) Note the pI and MW of
the protein found and its Sequence Code. Select the single letter
sequence and copy it. ( Don't worry about including the sequence
numbers - subsequent programs will remove them). See example for an
unrelated protein .
(2) Finding
mammalian proteins similar to your protein
Then click the
following button to access the BLAST sequence
searching
program at http://www.ebi.ac.uk/blastall/
Paste your
sequence into the box following "Enter or Paste a
Protein
Sequence in any format". Then hit Run Blast
Wait until the
answers are loaded into your page. Then scroll down
the
page until you reach "Sequences producing High-scoring Segment
Pairs:
". Search for any mammalian proteins, particularly Human and Mouse,
to which your protein has similarity.
(3) Identifying
domains in the protein through sequence similarity
Open SMART
web-server (Simple Modular Architecture Research Tool)
http://smart.embl-heidelberg.de/ Paste your
sequence into the sequence window. Then hit "Sequence Smart".
Hit "Print Screen" on your keyboard to capture an image of the domain
structure that the server finds. This image can be pasted into
PowerPoint (see below)
Click the
domains shown in the diagram to learn
more about them and record their putative functions.
Making a
PowerPoint slide
You must make a
single PowerPoint Slide summarising your results. You
may use the example file shown in the course book as a template. It can
be downloaded
Your slide
should include
The image of the gel, annotated to highlight the band binding to
Anyport and notes on design of the control lane.
The image of the domain structure of the interactor that was
identified, showing its sequence database accession number, pI and MW
and identify one similar mammalian protein (only the best human
match, otherwise only the best mouse match).
A model for how the system may be working
Instructions for
using PowerPoint are
Instructions for
uploading the PowerPoint Slide are